1. 강화학습 에이전트의 '눈'과 '손발' 설계
베이스라인 환경 구축에 이어, 이번 주차에는 강화학습 에이전트(PPO)가 환경을 인식하고 상호작용할 수 있도록 관측 상태(State)와 행동(Action) 공간을 정의했습니다. 에이전트가 복잡한 다차선 도로 상황을 효율적으로 학습할 수 있도록 데이터를 정밀하게 가공하는 데 집중했습니다.
1-1. 관측 상태 (Kinematics Observation)
에이전트가 주변 차량의 동태를 파악하는 '눈'의 역할을 하도록 Kinematics 타입의 Observation을 설정했습니다.
- 관측 대상: 에이전트 자신을 포함해 주변에서 가장 가까운 15대의 차량
- 추출 피처(Features):
[presence, x, y, vx, vy](차량 존재 여부, 좌표, 좌표, 축 속도, 축 속도) - 데이터 정규화: 신경망의 안정적인 학습을 위해
normalize=True옵션을 적용하여 모든 상태 값을 0~1 사이의 상대적인 수치로 스케일링했습니다.
결과적으로 에이전트는 매 스텝마다 (15, 5) 형태의 2차원 Numpy 행렬 데이터를 환경으로부터 전달받게 됩니다.
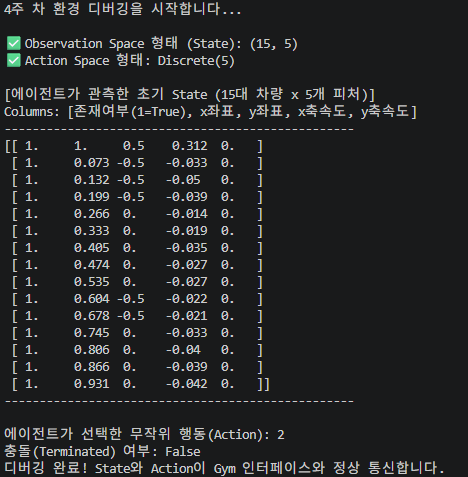
터미널에 출력된 에이전트 관측 상태
1-2. 이산 행동 공간 (Discrete Meta Action)
에이전트의 '손발'이 될 Action Space는 조향각이나 페달 압력을 직접 조절하는 Low-level 제어 대신, 5가지 의사결정을 내리는 고수준의 DiscreteMetaAction을 채택했습니다.
0: 좌측 차선으로 변경 (LANE_LEFT)1: 현재 상태 및 속도 유지 (IDLE)2: 우측 차선으로 변경 (LANE_RIGHT)3: 가속 (FASTER)4: 감속 (SLOWER)
이 설정을 통해 에이전트의 행동 탐색(Exploration) 공간을 압축하고, 학습 수렴 속도를 비약적으로 높일 수 있습니다.
2. 시공간 다이어그램용 Logging Wrapper 구축
향후 10주 차에 예정된 '시공간 다이어그램(Time-Space Diagram)' 시각화를 대비하여, 매 스텝마다 전체 차량의 궤적(Trajectory)과 속도 데이터를 추출하는 로직을 고도화했습니다.
기존에는 시뮬레이션 메인 루프 안에 로깅 코드가 섞여 있어 유지보수가 어려웠으나, 이를 Gym의 Wrapper 클래스를 상속받은 PhantomJamLoggingWrapper 객체로 분리했습니다.
- 자동화: 에피소드가 종료(
terminated또는truncated)되면 내부 메모리에 쌓인 데이터를 자동으로 CSV 파일로 저장합니다. - 모듈화: 학습 알고리즘 코드가 환경 로깅 로직에 간섭받지 않아 코드가 훨씬 간결해졌습니다.
3. 환경 디버깅 및 프로젝트 폴더 구조 리팩토링
3-1. OpenAI Gym 인터페이스 통신 테스트
설계된 환경을 디버깅하기 위해 무작위 행동(env.action_space.sample())을 에이전트에게 지시했습니다. 고밀도 환경(차량 60대) 특성상 에이전트가 무작위로 핸들을 꺾자마자 주변 차량과 충돌하여 에피소드가 즉시 종료(Terminated=True)되는 것을 확인했습니다.
이는 시뮬레이터의 물리 엔진과 충돌 페널티 감지 시스템이 완벽하게 작동하고 있음을 증명하며, 향후 PPO 알고리즘이 충돌을 피하는 방향으로 학습할 강력한 동기가 될 것입니다.
3-2. 폴더 구조 리팩토링
파일이 늘어남에 따라 프로젝트를 더 체계적으로 관리하기 위해 디렉토리 구조를 전면 개편했습니다.
소스 코드는 src/, CSV 로그 파일은 logs/, 시각화 이미지는 results/ 폴더로 분리했으며, 파이썬의 os.makedirs를 활용해 코드 실행 시 누락된 폴더가 자동으로 생성되도록 파이프라인의 안정성을 더했습니다.