RL, Reinforcement Learning Basics
1. 강화학습이란?
Reinforcement Learning, RL (강화학습) : 머신러닝의 한 분야로, 에이전트(Agent)가 환경(Environment)과 상호작용하며 시행착오를 통해 학습하는 방법을 연구하는 학문.
[note]
정답이 주어진 데이터를 외우는 것이 아니라, 어떤 행동을 했을 때 주어지는 피드백을 지표 삼아 "어떻게 행동해야 가장 좋은 결과를 얻을 수 있는지"를 스스로 깨우치는 과정!
-> 에이전트의 행동에 대해 보상/처벌을 가하면, 에이전트가 미래에 해당 행동을 반복/지양할 가능성이 높아진다는 개념을 공식화한 것!
2. 주요 구성 요소
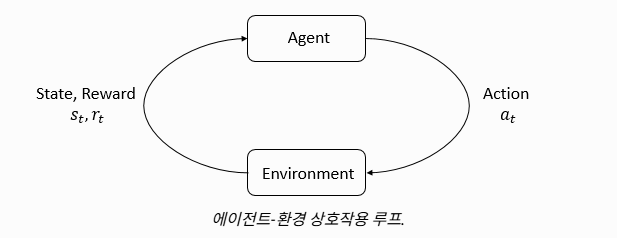
2-1. Agent (에이전트)
: Environment(환경) 속에서 State(상태)를 Observation(관찰)하고, 자신의 Policy(정책)에 따라 판단하여 Action(행동)을 내리며, 그 결과로 받는 Reward(보상)을 통해 스스로 학습해 나가는 주체!
-> Agent의 목표는 Return(누적 보상)을 최대화하는 것.
(이해가 되지 않아도 걱정 마세요. 아래에 모든 용어 설명이 이루어질 겁니다!)
2-2. Environment (환경)
: Agent(에이전트)가 상호작용하는 세계
-> 이때, 환경은 에이전트의 행동에 따라 변화하나, 스스로 변화하기도 함.
[note]
Agent는 Environment로부터 reward 신호를 인지하는데, 이 신호는 현재 세계 상태가 얼마나 좋거나 나쁜 지를 나타내는 수치
- 우리는 위에서 언급된 강화학습의 기초적 정의와 구성 요소, 방법에 대해 이해하기 위해 다음과 같은 용어를 정리하려고 합니다!
- states(상태) / observations(관찰)
- action(행동) / action spaces(활동 공간)
- policies(정책)
- trajectories(궤적)
- Reward(보상) / Return(누적 보상)
- the RL optimization problem(강화학습 최적화 문제)
- value function(가치 함수)
...
3. 용어 정리
3-1. States(상태) / Observations(관찰)
우리가 다루게 될 highway-env 자율주행 시뮬레이션 환경
-
정의:
- 상태(State): 환경에 대한 모든 정보를 담고 있는 완벽한 설명
- 관찰(Observation): 에이전트가 센서 등을 통해 받아들이는 상태의 일부(제한된 정보)
[note]
이때 환경의 모든 정보를 에이전트가 볼 수 있으면 Fully Observed(완전 관측)라고 하며, 이는 마르코프 결정 과정(MDP)의 기본 전제가 됩니다. 반대로 자율주행처럼 주변의 일부만 볼 수 있는 현실적인 상황은 Partially Observed(부분 관측)라고 하며, 부분 관측 마르코프 결정 과정(POMDP)이라고 부릅니다.💡 [개념 보충] 마르코프 결정 과정(MDP)이란?MDP(Markov Decision Process)는 강화학습에서 에이전트가 의사결정을 내리는 과정을 수학적으로 엄밀하게 정의해 놓은 틀입니다. 쉽게 말해, "현재 상황에서 어떤 행동을 해야 가장 좋은 결과를 얻을 수 있을까?"를 계산하기 위해 환경을 모델링한 도면입니다.
가장 핵심이 되는 건 마르코프 성질(Markov Property)입니다. "미래는 오직 '현재'의 상태와 행동에 의해서만 결정되며, 과거의 역사는 전혀 상관없다"는 뜻을 담고 있습니다.
MDP는 기본적으로 5가지 핵심 요소로 구성되어 있습니다.
- S (State): 에이전트가 인식할 수 있는 환경의 모든 상태 집합
- A (Action): 에이전트가 특정 상태에서 취할 수 있는 모든 행동의 집합
- P (Transition Probability): 상태 전이 확률. 현재 상태 에서 행동 를 했을 때, 다음 상태 로 넘어갈 확률
- R (Reward): 보상 함수. 상태 에서 행동 를 취해 다음 상태 로 넘어갔을 때 받는 피드백
- (Discount Factor): 할인율. 미래에 받을 보상을 현재 가치로 환산할 때 곱해주는 숫자
-
예시: 우리가 사용할
highway-env기반의 도로 교통 시뮬레이션 환경에서 '상태'는 도로 위 모든 차량의 정확한 위치와 속도입니다. 하지만 자율주행 에이전트는 주변 반경의 일부 차량 정보만 '관찰'하여 판단을 내립니다. -
수식:
-
상태:
-
관찰:
- 완전 관측 상태에서는 가 성립합니다.
-
-
코드 (Python): 시뮬레이션 환경을 초기화하고 첫 관찰값을 받아옴
obs, info = env.reset()
3-2. Action(행동) / Action Spaces(활동 공간)
-
정의:
-
행동(Action): 에이전트가 환경에 가하는 조작
-
활동 공간(Action Space): 에이전트가 선택할 수 있는 모든 유효한 행동들의 집합.
- 선택지가 정해져 있으면 이산(Discrete), 연속적인 수치면 연속(Continuous) 공간이라고 함.
-
-
예시: 차선 변경, 가속, 감속 등 명확하게 나누어진 5가지 선택지 중에서 하나를 고르는 '이산 활동 공간'을 예로 들 수 있습니다.
-
수식:
-
행동:
-
활동 공간:
- 이때 Action은 Action space에 속함. ()
-
-
코드 (Python): 결정한 행동을 시뮬레이터에 전달하여 환경을 한 스텝 진행시킵니다.
env.step(action)
3-3. Policies(정책)
-
정의: 에이전트가 특정 상태에서 어떤 행동을 할지 결정하는 '규칙'이자 에이전트의 '뇌'.
결과가 무조건 하나로 정해진 결정론적(Deterministic) 정책과, 확률에 따라 행동이 달라지는 확률론적(Stochastic) 정책이 있음!
- OpenAI Spinning Up에서는 특히 확률론적 정책을 강조합니다. 이산 행동 공간에서는 범주형 분포(Categorical Distribution)를, 연속 행동 공간에서는 대각 가우시안 분포(Diagonal Gaussian Distribution)를 주로 사용한다는 점을 알아두면 좋습니다.
-
예시: 학습 중에는 다양한 시도를 위해 주사위를 굴리는 확률론적 정책을 쓰지만, 실전에 투입할 때는 가장 정답일 확률이 높은 행동만 수행하는 결정론적 정책을 사용합니다.
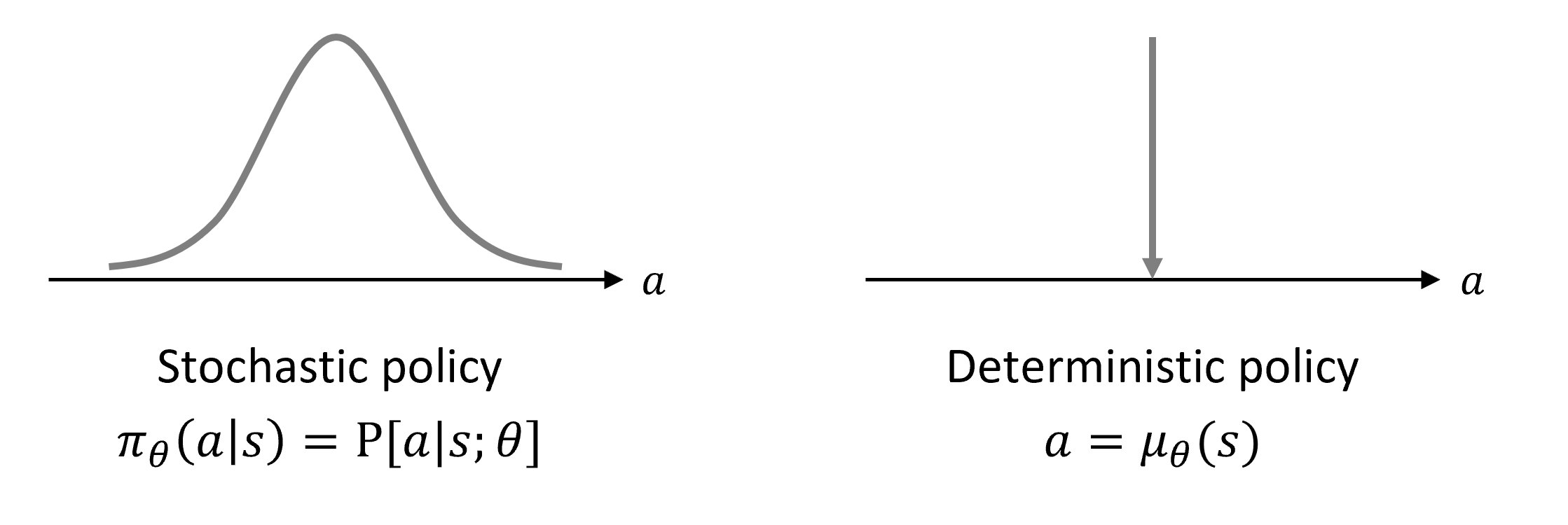
결정론적 정책(좌)과 확률론적 정책(우)의 차이
-
수식:
- 결정론적:
- 확률론적: (상태 에서 행동 를 할 확률 분포)
-
코드 (Python): 학습된 모델(정책)에게 현재 상태를 주고 다음 행동을 예측하게 합니다.
action, _states = model.predict(obs, deterministic=True)
3-4. Trajectories(궤적)
-
정의: 에이전트가 환경 속에서 경험한 상태와 행동들의 연속된 나열.
-> 에피소드(Episode) 하나가 시작해서 끝날 때까지의 기록 전체를 의미함.[note]
에피소드(Episode): 에이전트가 환경과 상호작용하여 시작 상태에서 종료 상태(Terminal State)에 이르기까지의 완전한 시나리오/작업 단위.💡 [개념 보충] 알아두면 좋은 내용세계의 최초 상태 는 시작 상태 분포(start-state distribution)에서 무작위로 추출됩니다.
상태 전이(시간 에서의 상태와 시간 에서의 상태 사이에서 세계에 일어나는 일) 는 환경의 자연 법칙에 의해 지배되며, 가장 최근의 행동에만 의존합니다.
- 상태 전이는 결정론적일 수도 있고, 확률적일 수도 있습니다.
- 에이전트의 행동은 해당 에이전트의 정책에 따라 이루어집니다.
-
예시: 자율주행 에이전트가 고속도로에 진입해서 목적지에 도착할 때까지의 '1회 주행 블랙박스 녹화 영상' 전체가 하나의 궤적입니다.
-
수식: 궤적은 기호 타우()로 표기합니다.
특정 궤적이 발생할 확률은 환경의 상태 전이 확률(Transition Probability)과 에이전트의 정책 확률의 곱으로 엄밀하게 표현할 수 있습니다.
-
코드 (Python): PPO 알고리즘 등에서는 에이전트가 돌아다니며 겪은 이 궤적 데이터를 메모리 버퍼에 자동으로 수집하여 학습에 활용합니다.
3-5. Reward(보상) / Return(누적 보상)
-
정의:
- 에이전트는 행동의 대가로 즉각적인 보상(Reward) 을 받음.
- 그리고 이 보상들을 에피소드 끝까지 모두 합친 것이 누적 보상(Return)!
- 먼 미래의 보상일수록 가치를 깎아서 더하는 방식(Discounted Return)이 강화학습에서 가장 널리 쓰임!
-
예시: 무리하게 끼어들면 당장 +1점(Reward)을 받지만, 그로 인해 뒤차들이 급브레이크를 밟아 나중에 큰 벌점을 받는다면 전체 Return은 마이너스가 됩니다. 에이전트는 할인율(γ)을 고려하여 당장의 이득보다 미래의 전체 흐름을 보는 법을 배웁니다.
-
수식:
- 순간 보상:
- 할인된 누적 보상 (Discounted Return):
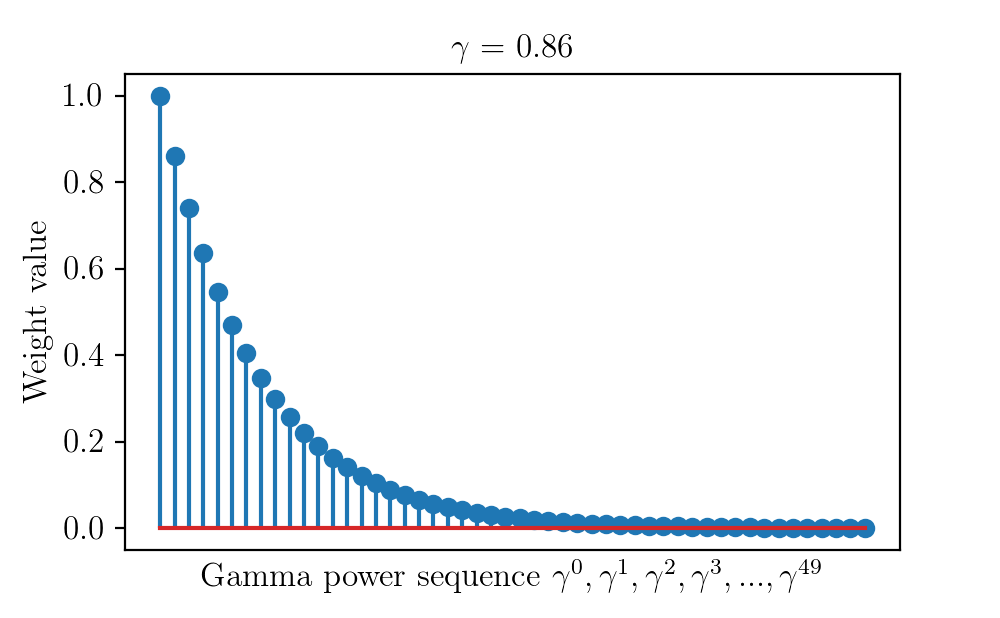
시간이 지날수록 할인율(gamma)에 의해 감소하는 보상의 가치
- 코드 (Python): 모델을 세팅할 때 파라미터로 할인율()을 지정해 줍니다.
model = PPO("MlpPolicy", env, gamma=0.99)
3-6. The RL Optimization Problem(강화 학습 최적화 문제)
-
정의: 강화학습의 궁극적인 목표로, 무수히 많은 정책들 중에서, 예상되는 누적 보상(Return)의 기댓값을 가장 극대화(Maximize) 하는 단 하나의 최적의 정책을 찾는 수학적 과정!
-
예시: "어떤 타이밍에 차선을 바꾸고 감속해야 도로 전체의 정체가 가장 완벽하게 해소되는가?"에 대한 절대적인 정답 알고리즘을 찾아내는 전체 프로젝트의 목표와 같습니다.
-
수식: 기대 수익률 를 최대화하는 최적의 정책 를 찾습니다.
- 코드 (Python):
learn함수를 호출하게 되면, 해당 최적화 수학 문제가 백그라운드에서 풀리기 시작합니다.model.learn(total_timesteps=20000)
3-7. Value Function(가치 함수)
-
정의: 특정 상태()에 있을 때, 앞으로 얻을 수 있는 '예상 누적 보상'의 기댓값. 즉, 지금 상황이 에이전트에게 "얼마나 유리한가?"를 수치화한 지표!
Spinning Up에서는 크게 두 가지 가치 함수를 명확히 구분하여 알아야 한다고 강조합니다.
- 상태-가치 함수 (State-Value Function): 특정 상태 에 있을 때의 가치.
- 행동-가치 함수 (Action-Value Function, Q-Function): 특정 상태 에서 특정한 행동 를 취했을 때의 가치.
-
예시: 바둑의 '형세 판단' 능력과 같습니다. 당장 눈앞에 떨어지는 보상이 0점이더라도, 내 차 앞에 뻥 뚫린 차선이 펼쳐져 있는 상태라면 가치 함수는 "이 상황은 앞으로의 가치가 아주 높다!"라고 평가합니다.
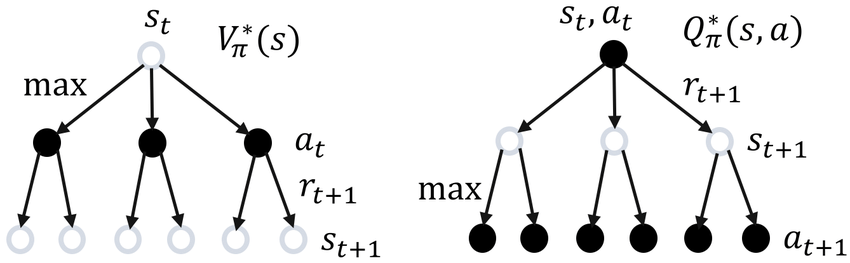
상태-가치 함수(V)와 행동-가치 함수(Q)의 평가 기준점 차이
-
수식: 정책 를 따랐을 때, 상태 에서 시작하여 얻게 될 누적 보상의 기댓값입니다.
- 상태-가치 함수 :
- 행동-가치 함수 :
OpenAI Spinning Up에서는 가치 함수를 크게 '현재 정책을 따르는가()', 아니면 '절대적으로 최적의 정책을 따르는가()'에 따라 4가지로 명확히 나누어 정의합니다.
- 상태-가치 함수 (On-Policy State-Value Function): 에이전트가 상태 에서 시작하여, 이후 계속 현재 정책 를 따를 때 얻을 것으로 기대되는 누적 보상입니다.
- 행동-가치 함수 (On-Policy Action-Value Function): 에이전트가 상태 에서 임의의 행동 를 먼저 한 번 취하고, 그 이후부터는 현재 정책 를 따를 때 기대되는 누적 보상입니다.
- 최적 상태-가치 함수 (Optimal State-Value Function): 에이전트가 상태 에서 시작하여, 무수히 많은 정책 중 가장 완벽한 최적의 정책을 따를 때 얻을 수 있는 최대 누적 보상입니다.
- 최적 행동-가치 함수 (Optimal Action-Value Function): 에이전트가 상태 에서 임의의 행동 를 취하고, 그 이후부터는 가장 완벽한 최적의 정책을 따를 때 얻을 수 있는 최대 누적 보상입니다.
요약하자면: 는 "이 상태가 얼마나 좋은가?"를, 는 "이 상태에서 이 행동을 하는 게 얼마나 좋은가?"를 평가합니다. 기호에 별표()가 붙으면 "가장 완벽하게 행동했을 때"를 가정한 절대적인 기준점이 됩니다!
- 코드 (Python): PPO와 같은 Actor-Critic 구조에서는, 상황의 유불리를 판단하는 가치 함수(Critic) 신경망을 따로 호출해 볼 수 있습니다.
value = model.policy.predict_values(obs)
3-8. Advantage(어드밴티지) / Advantage Function(어드밴티지 함수)
-
정의:
- 어드밴티지(Advantage): 특정 상태에서 어떤 행동을 취하는 것이, 그 상태에서 평균적으로 기대할 수 있는 결과보다 얼마나 더 좋은지(또는 나쁜지)를 수치화한 '상대적인 이득 값'.
- 어드밴티지 함수(Advantage Function): 특정 상태()와 행동()이 주어졌을 때, 정책 를 기준으로 해당 행동의 어드밴티지 값을 수치적으로 계산해 내는 '함수'.
-
예시: 뻥 뚫린 고속도로(상태)에서는 어떤 행동을 해도 기본적으로 예상 보상이 높습니다. 이때 가속을 하는 것이 단순히 현재 속도를 유지하는 것(평균 기대치)보다 얼마나 더 큰 이득을 가져다주는지 그 상대적인 차이가 바로 '어드밴티지'이며, 이 차이를 계산하는 공식이 '어드밴티지 함수'입니다.
-
수식: 행동-가치 함수()에서 상태-가치 함수()를 빼서 계산합니다.
- 코드 (Python): PPO 알고리즘은 내부적으로 이 어드밴티지 값을 사용하여, 평균보다 좋은 행동을 할 확률은 높이고 나쁜 행동을 할 확률은 낮추는 방식으로 학습합니다.
3-9. Bellman Equation(벨만 방정식)
-
정의: 현재 상태의 가치와 다음 상태의 가치 사이의 일관된 수학적 관계를 나타내는 방정식.
강화학습의 모든 알고리즘이 뼈대로 삼는 가장 중요한 수식!
-
특징: 현재의 가치( 또는 )는 즉각적으로 받을 보상과 다음 상태에서 얻을 예상 가치의 합으로 쪼개서 계산할 수 있다는 재귀적인 특성을 가집니다.
-
수식: 앞서 살펴본 4가지 가치 함수에 각각 대응하는 4개의 벨만 방정식이 존재합니다.
- 상태-가치 함수의 벨만 방정식:
- 행동-가치 함수의 벨만 방정식:
- 최적 상태-가치 함수의 벨만 방정식:
- 최적 행동-가치 함수의 벨만 방정식:
4. 실전 적용
-
개요: 지금까지 배운 마르코프 결정 과정(MDP) 구성 요소들을 도로 교통 시뮬레이션 환경에 대입하여, 다수 차량의 흐름을 개선하는 자율주행 물리적 AI(Physical AI) 에이전트를 어떻게 설계할지 논의해 봅니다.
이 내용은 이후 직접 실험을 통해 수행해볼 예정입니다!
-
모델링 예시:
- 에이전트: 도로 위를 주행하는 개별 자율주행 차량
- 상태(State): 주변 차량들의 위치, 속도, 차간 거리, 도로 형태
- 행동(Action): 가속, 감속, 차선 유지, 좌/우 차선 변경
- 보상(Reward): 충돌 시 강한 페널티, 목표 속도 도달 시 기본 보상, 그리고 에이전트의 행동으로 인해 전체 교통 체증이 완화되어 도로의 평균 속도가 올라갈 때 주어지는 추가 보상
-
의의: 단일 에이전트의 이기적인 주행이 아니라 환경 전체의 누적 보상을 극대화하는 방향으로 정책이 학습되면, 원인 모를 유령 정체 현상을 해결하는 강화학습 시스템을 성공적으로 구현할 수 있습니다.