Shockwave & MOBIL
교통 정체 파동과 MOBIL 모델 이해하기
강화학습 에이전트(자율주행 차량)를 학습시키기 위해서는 우리가 풀고자 하는 '문제(정체 파동)' 가 무엇인지, 그리고 에이전트 주변을 둘러싼 환경의 '규칙(MOBIL 모델)' 이 어떻게 작동하는지 알아야 합니다.
1. 유령 정체와 정체 파동 (Phantom Traffic Jam & Shockwave)
1-1. 유령 정체란?
사고나 병목 구간(톨게이트, 차선 감소 등)과 같은 명확한 원인이 없는데도 불구하고 고속도로 위에서 원인을 알 수 없이 발생하는 교통 체증을 말합니다.
1-2. 정체 파동(Shockwave)의 발생 원리
유령 정체의 근본적인 원인은 '인간 운전자의 반응 지연' 과 '과잉 반응(Over-braking)' 에 있습니다.
- 트리거 발생: 선두 차량 중 한 대가 무리하게 차선을 변경하거나 살짝 브레이크를 밟습니다.
- 반응 지연과 과잉 제동: 바로 뒤따르던 차량은 앞차가 느려진 것을 인지하고 안전거리를 확보하기 위해 앞차보다 조금 더 강하게 브레이크를 밟습니다.
- 파동의 역방향 전파: 이 과정이 꼬리를 물고 뒤로 이어지면서 감속의 폭이 눈덩이처럼 커집니다. 결국 한참 뒤에 있는 차량은 도로가 텅 비어있는데도 완전히 멈춰 서야 하는 상황이 발생합니다. 이것이 마치 물결처럼 뒤로 전달된다고 하여 정체 파동(Shockwave) 이라고 부릅니다.
1-3. 시공간 다이어그램 (Time-Space Diagram)
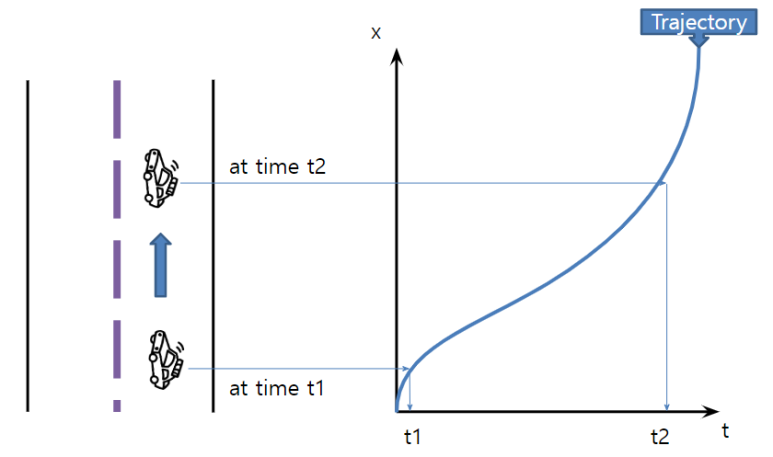
Time-Space Diagram
차량들의 주행 궤적을 X축(시간)과 Y축(위치)으로 나타낸 그래프입니다. 차량들이 잘 달리다가 특정 시점부터 궤적이 꺾이며(감속), 이 감속 구간이 시간이 지날수록 도로 뒤쪽(Y축의 아래쪽)으로 이동하는 V자 형태의 띠를 뚜렷하게 관찰할 수 있습니다.
우리의 PPO 에이전트는 바로 이 정체 파동을 흡수하는 방파제 역할을 수행해야 합니다. 주변 차량의 흐름을 읽고 적절한 타이밍에 차간 거리를 벌려 부드럽게 감속함으로써, 뒷차로 이어지는 과잉 제동의 고리를 끊어내는 것이 프로젝트의 핵심입니다.
2. MOBIL 모델 (차선 변경 알고리즘)
highway-env 시뮬레이션 환경에 등장하는 수많은 일반 차량(NPC)들은 어떻게 차선 변경을 결정할까요? 딥러닝이 아니라, MOBIL (Minimizing Overall Braking Induced by Lane change) 이라는 아주 정교한 수학적 규칙(Rule-based) 모델을 따릅니다.
우리의 자율주행 에이전트는 딥러닝(PPO) 기반인데, 왜 도로 위의 수많은 일반 차량(NPC)들은 MOBIL이라는 규칙 기반(Rule-based) 모델을 사용할까요? 여기에는 시뮬레이션 설계의 중요한 현실적 이유들이 있습니다.
- 완벽한 통제력 (화이트박스 vs 블랙박스): 딥러닝은 내부 연산을 알 수 없는 '블랙박스'라 돌발 행동의 원인을 파악하기 어렵습니다. 반면 MOBIL은 이타심 지수() 같은 변수를 조절해 연구자가 100% 통제할 수 있는 투명한 환경을 제공합니다.
- 연산 자원 집중 (시뮬레이션 속도): 수십 대의 차량이 매초 딥러닝 추론을 돌리면 시뮬레이션이 극도로 느려집니다. 가벼운 사칙연산인 MOBIL을 써서, 비싼 컴퓨팅 파워(GPU)를 오직 주인공(PPO 에이전트)의 반복 학습에만 몰아주기 위함입니다.
- 학습의 안정성 (고정된 과녁): 주변 차량들까지 스스로 행동 패턴을 계속 바꾸면, 에이전트 입장에서는 룰이 매번 바뀌는 게임을 하는 셈이 되어 학습이 붕괴될 위험이 큽니다. 일관된 수학 수식으로 움직이는 NPC들은 에이전트가 학습하기 가장 좋은 '안정적인 훈련 파트너'가 되어줍니다.
MOBIL 모델은 차량이 차선을 바꾸기 전, 정확히 두 가지 조건을 검사합니다.
2-1. 안전 조건 (Safety Criterion)
"내가 끼어들었을 때, 뒷차가 사고를 피하려고 너무 급브레이크를 밟게 만들지는 않는가?"
차선을 변경한 후, 새 차선의 뒷차(새로운 Follower)가 감당해야 하는 감속도()가 우리가 설정한 안전 기준치() 보다 커야 합니다. (즉, 너무 강한 급제동을 유발하면 차선을 바꾸지 않습니다.)
2-2. 이득 조건 (Incentive Criterion)
"내가 차선을 바꾸면, 나뿐만 아니라 주변 차량들도 전체적으로 이득을 보는가?"
단순히 나 혼자 빨리 가겠다고 차선을 바꾸는 것이 아니라, 나의 가속 이득과 타인(주변 차량)의 가속/감속 손익을 함께 계산하여 그 총합이 특정 임계값()을 넘어야만 차선을 변경합니다.
- : 차선 변경 후의 가속도 / : 차선 변경 전의 가속도
- 첨자 (나 자신), (새 차선 뒷차), (원래 차선 뒷차)
2-3. 핵심 파라미터: 이타심 지수 ()
위 수식에서 가장 중요한 변수는 (Politeness factor, 이타심 지수) 입니다.
- : 타인의 손해는 전혀 고려하지 않고, 오직 내 속도가 빨라질 때만 차선을 바꾸는 이기적인 운전자입니다. (정체 파동의 주범!)
- : 나보다 주변 차량의 흐름을 100% 동등하게 배려하는 완벽한 이타적 운전자입니다.
3. 결론: 왜 강화학습(RL)이 필요한가?
MOBIL 모델은 매우 훌륭한 알고리즘이지만, 미리 정해진 수식과 규칙(Rule) 안에서만 움직입니다. 상황이 복잡해지거나 다수의 이기적인() 차량이 섞여 있으면 여전히 정체 파동을 막아내지 못합니다.
반면, 우리가 학습시킬 PPO 에이전트는 이런 고정된 규칙이 없습니다. 오직 '도로 전체의 평균 속도 향상'이라는 보상(Reward)을 좇아 무수히 많은 시행착오를 겪으며, 인간이 수식으로 정의하기 힘든 창의적이고 유연한 타이밍을 스스로 깨우치게 됩니다.